Come vuole il mantra che si trova come incipit di quasi ogni trattazione del fenomeno Big Data , il volume dei dati a disposizione di chi voglia utilizzarli per comprendere, prevedere, descrivere meglio la realtà circostante è cresciuto a dismisura e continuerà a farlo in modo esponenziale.
IL BOOM DEI BIG DATA. La stessa dinamica di crescita ineluttabile si osserva provando a digitare “Big Data” in Google Trends. Una crescita impetuosa che inizia nel 2011 e che continua sino ad oggi. Curiosamente (o forse no) proprio nel momento in cui il volume di dati a disposizione cresce si affievolisce il focus (sempre osservando Google trend) sugli strumenti di analisi. E non solo sui più classici, ma anche su quelli più innovativi che sino a qualche anno fa promettevano di rivoluzionare il mondo della BI e che proprio nell’attuale mare magnum di dati dovrebbero trovare il loro terreno di coltura.
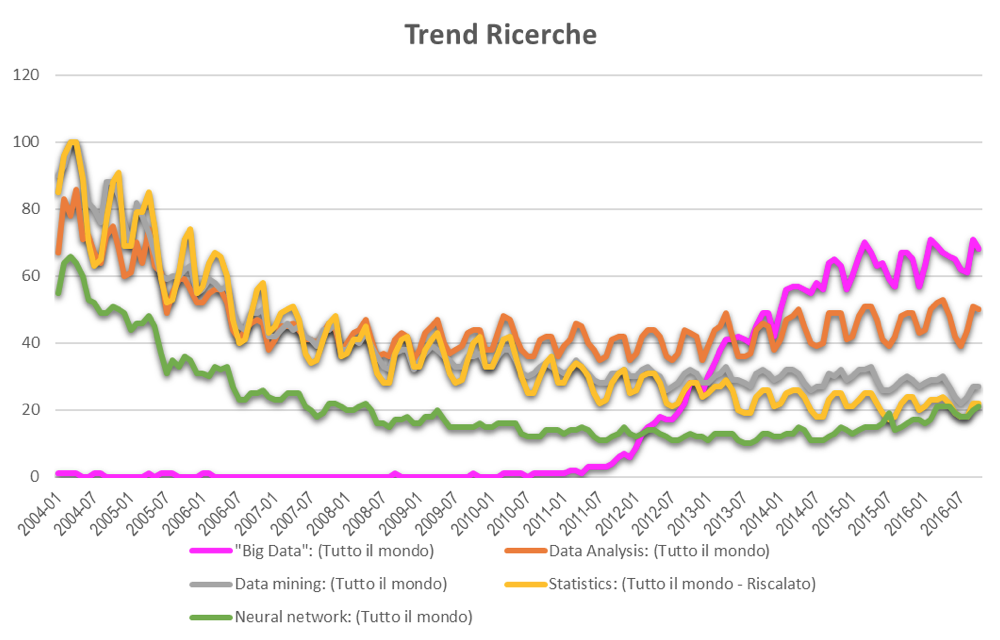
Perché? Perché l’entusiasmo per il fenomeno Big Data si è rapidamente tradotto nell’idea che le famose tre V dei dati (volume, velocità, varietà) fossero di per sé garanzia di facilità. Facilità nel produrre dati, nell’archiviarli e, con il supporto di strumenti informatici sempre più performanti, anche nell’elaborarli. E da lì a pensare che la facilità di utilizzo dei dati si potesse tradurre ineluttabilmente in una garanzia di uso proficuo il passo è stato breve. Di fatto negli ultimi anni si è posto l’accento su algoritmi sempre più complessi e, mi si passi il termine, su meta algoritmi (algoritmi che si nutrono di algoritmi) che hanno ridato linfa all’attenzione sull’analisi dei dati allontanandola però da approcci più classici per spingerla sempre più verso il terreno dell’intelligenze artificiale.
Ancora in Google Trends (normalizzando i dati – deciderebbe di farlo in automatico un algoritmo?), si vede bene come l’interesse per l’analisi dei dati non sia più alimentato da quello per la statistica, ma da quello per l’apprendimento automatico.
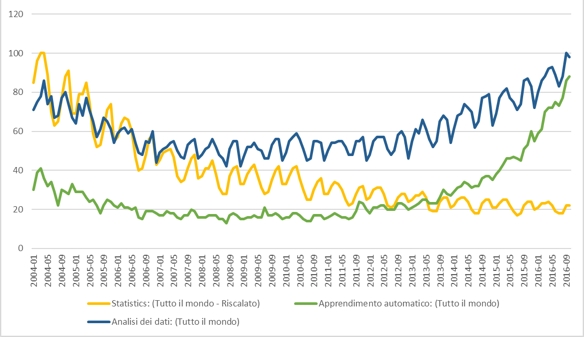
L’analisi dati diventa così un problema di ingegneria informatica, di spazio disco, di processori, di calcolo parallelo, la complessità del processo di definizione operativa delle questioni oggetto di ricerca demandata alla complessità procedurale, il ruolo umano trasmesso per implementazione ad algoritmi che, quasi essere antropomorfi, il ricercatore deve educare (training) e valutare.
LA NECESSITÀ DI INTERPRETARE.
È la via corretta? A mio avviso lo è solo in parte, perché la questione è più complessa. A cosa servono i dati? Servono per simulare, interpretare, descrivere, spiegare (…) le cose che accadono. Quali siano poi queste cose dipende ovviamente dal contesto di applicazione. Ma se parliamo di Business Intelligence o ancora meglio di Customer Intelligence, anche considerando compiti di simulazione o di previsione, la potenza di calcolo da sola non è garanzia di successo, e ancor di più questo è vero quando ci interessiamo di spiegazione o di interpretazione. Nella Customer Intelligence l’analisi dei dati, Big o meno che siano, è parte di un processo di ricerca che per essere efficace non può prescindere da teorie e modelli interpretativi e non può limitarsi a processi induttivi. Lo sguardo del ricercatore (data scientist) deve poter informare i dati, trasmettere loro la sua visione del problema, la sua intelligenza. Per questo l’efficacia dell’utilizzo dei dati in certi contesti non può prescindere a mio avviso dalla loro interpretazione. Per questo nel momento in cui si deve riprodurre il comportamento di un cliente un algoritmo molto sofisticato può essere un validissimo aiuto, ma non può essere la soluzione. Perché è guidato unicamente da logiche matematiche, dalla ricerca di un minimo e da solo non può ricostruire la complessità del problema se questa non è stata gestita, tradotta, ridotta dal disegno complessivo del progetto.
Perché se parafrasando Moritz Shlick si può dire che il significato di una proposizione è nel metodo che l’ha generata, lasciare tutto il processo di analisi dati all’interno di una black box informatica è un rischio non da poco.
di Gianluca Bo







